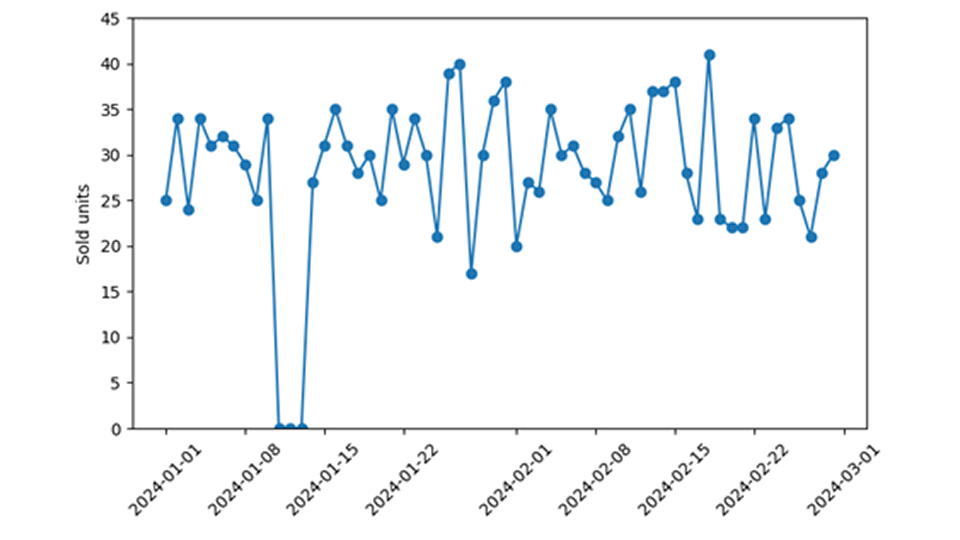
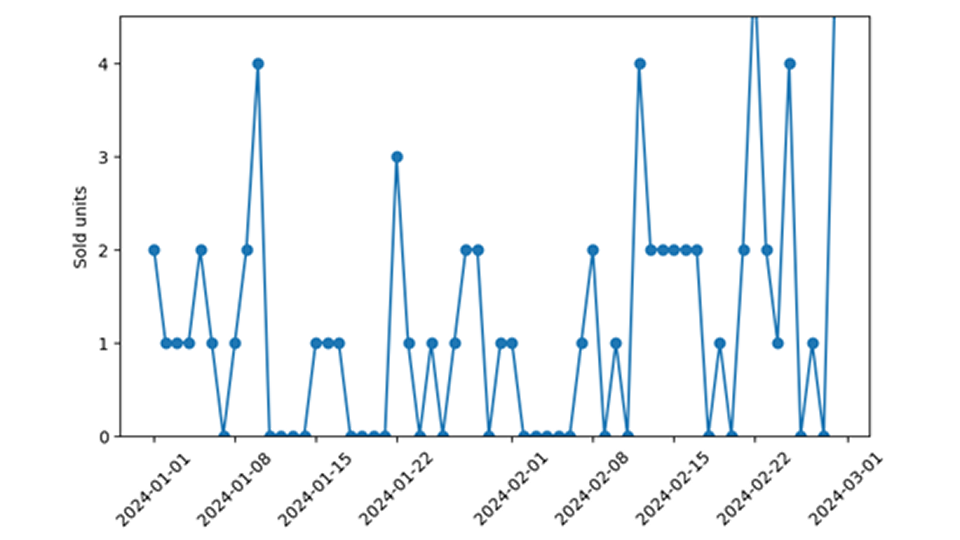
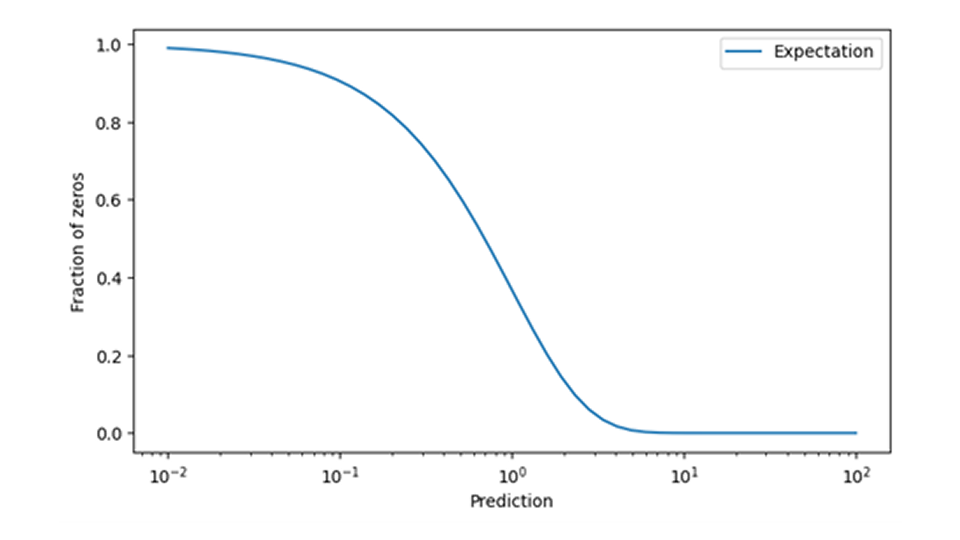
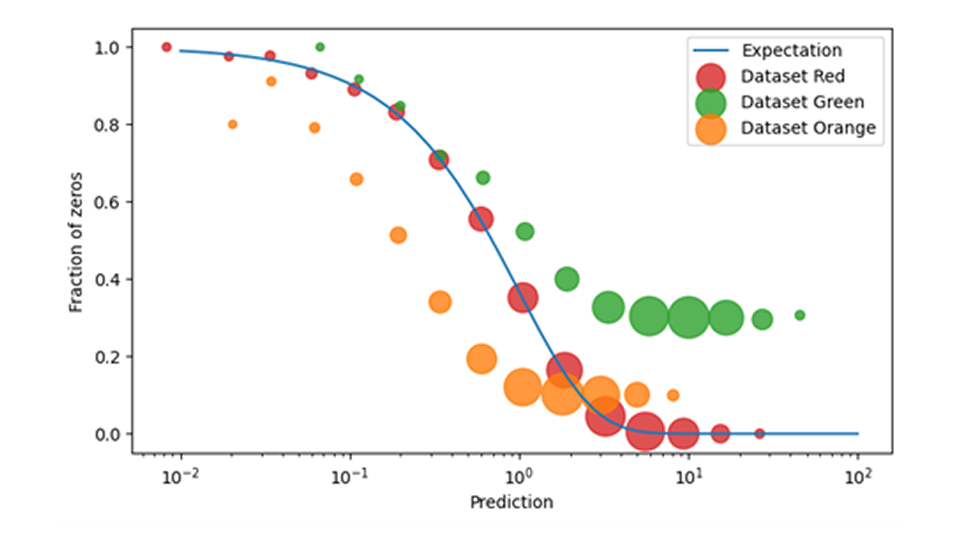
Bei der Absatzprognose im Einzelhandel erfordern Null-Umsätze besondere Aufmerksamkeit beim Training und der Anwendung von Nachfragemodellen. Es ist schwierig , im Nachhinein festzustellen, ob bei einem Ereignis, bei dem keine Verkäufe erzielt wurden, tatsächlich eine verschwindende Nachfrage an einem bestimmten Tag vorlag (im Sinne von „niemand hat dieses Produkt aus dem Regal genommen“), oder ob das vorhergesagte Produkt einfach nicht verfügbar war (im Sinne von „das Produkt wurde gar nicht erst ins Regal gestellt“). Zum Glück lässt sich die Übereinstimmung der Daten mit dem Vorhersagemodell überprüfen, indem man die vorhergesagte Wahrscheinlichkeit, einen Wert von Null zu beobachten, mit der beobachteten Häufigkeit von Null-Verkaufsereignissen vergleicht. Wenn diese nicht gut übereinstimmen, d. h. wenn man Nullverkäufe viel häufiger oder viel seltener beobachtet als vorhergesagt, hat man ein größeres, aber klar definiertes Datenproblem diagnostiziert.
Existiert die Null, und wenn ja, auf wie viele Arten?
Die Zahl „Null“ entzieht sich erstaunlich lange der menschlichen Abstraktionsfähigkeit. Verschiedene antike Kulturen behandelten die „Abwesenheit von irgendetwas“ auf unterschiedliche Weise, und Wissenschaftshistoriker diskutieren noch immer darüber, wann und wie die Null als Symbol erfunden wurde und Teil des mathematischen Mainstreams wurde. Zum Beispiel enthalten die römischen Zahlen nicht einmal ein Symbol für Null, wahrscheinlich weil die Römer Zahlen für die Buchhaltung und nicht für die Arithmetik verwendeten. Aristoteles lehnte sogar die Idee ab, dass Null eine Zahl sei – wenn man nicht durch sie teilen kann, wozu ist sie dann gut? Im siebten Jahrhundert n. Chr. begann der indische Mathematiker und Astronom Brahmagupta, eine geschriebene Null zu verwenden und zu analysieren, die dann ihren Weg ins Chinesische und Arabische und über letzteres in die europäische Kultur fand.
Natürlich kennen Sie die Null und fühlen sich wohl damit, sie zu verwenden. Spulen wir also einige Jahrhunderte mathematischer Diskussionen vor zur Vorhersage der Einzelhandelsnachfrage mithilfe von künstlicher Intelligenz (KI) und maschinellem Lernen (ML). Ich behaupte hier, dass eine Art von Null nicht ausreicht. Für eine korrekte Beschreibung der Umsätze im Einzelhandel sind mindestens zwei unterschiedliche Nullkonzepte erforderlich. Einer der beiden Datensätze muss im Trainingsdatensatz beibehalten, der andere muss entfernt werden.
Einerseits kann ein Produkt verfügbar sein und der Öffentlichkeit angeboten werden: Das Geschäft ist geöffnet, die Kasse und alles andere funktioniert – aber einfach kein Kunde will es kaufen! In diesem Fall spiegelt das Ereignis „Null Verkäufe“ den tatsächlichen Mangel an Nachfrage und das fehlende Interesse der Verbraucher an diesem Produkt wider. Idealerweise wird unser Nachfrageprognosemodell von dieser Null nicht „überrascht“, da es eine nicht mikroskopische, sondern eine endliche Wahrscheinlichkeit für das Auftreten einer Null vorhergesagt hat.
Ein echter Nachfragemangel führt zu einer Nachfrage-Null, die ich von einer Verfügbarkeit-Null unterscheiden möchte. Diese letztgenannte Art von Null wird schlichtweg durch die Nichtverfügbarkeit des Produkts hervorgerufen. Dem Kunden wird das Produkt gar nicht erst angeboten, er hat keine Möglichkeit, es zu kaufen, selbst wenn er es wollte (wir werden es nie erfahren). Ich habe gestern kein iPhone für 99 Dollar verkauft – aber das ist eine nebensächliche Aussage, denn ich habe ja gar niemandem ein iPhone angeboten. Hätte ich es angeboten, hätte meine moderate Preisvorstellung eine beträchtliche Nachfrage ausgelöst und wahrscheinlich einen Käufer gefunden. Ich habe auch den gebrauchten Kinderwagen, den ich online angeboten habe, nicht verkauft – das ist aussagekräftiger, es gibt einfach keine Nachfrage. Während die Nachfrage-Nullstelle darauf hinweist, dass der Artikel nicht besonders beliebt ist (um es gelinde auszudrücken), hat die Nichtverfügbarkeit-Nullstelle nichts mit der tatsächlichen Nachfrage nach einem Artikel zu tun.
Nichtverfügbarkeit kann viele verschiedene Ursachen haben: Am wichtigsten ist, dass die Lagerbestände erschöpft sein können – dann gibt es schlichtweg nichts mehr zu verkaufen. Deshalb ist es großartig, die morgendlichen Aktienkurse in einer übersichtlichen Spalte unserer Daten zu haben. Dann können wir auf die in diesem Blogbeitrag beschriebenen Methoden zurückgreifen. Oftmals entspricht diese Datenqualität jedoch nicht dem Ideal: Aktieninformationen sind nicht verfügbar oder zumindest nicht gänzlich vertrauenswürdig. Aber selbst wenn verlässliche Lagerbestände erfasst würden, könnten wir nicht mit absoluter Sicherheit sagen, ob das Produkt tatsächlich im Regal steht – es könnte im Lager aufbewahrt werden, oder der Filialleiter könnte entschieden haben, dass es zu früh oder zu spät im Jahr ist, es anzubieten.
Nichtverfügbarkeit verschleiert die tatsächliche Nachfrage: Um die Nachfrage nach einem Artikel zu erfahren, müssen wir ihn anbieten. Ich habe keine Ahnung, wie groß die Nachfrage nach einem grünen Regenmantel mit rosa Sprenkeln sein wird, es sei denn, ich stelle ihn ins Regal, versehen ihn mit einem Preisschild und biete ihn den Kunden an. Wenn ein Produkt nicht angeboten wird, kann ich nur Vermutungen über die Nachfrage anstellen, sie aber nicht messen.
Zusammenfassend lässt sich sagen, dass meine Konzepte von Null folgende sind: Die wohlerzogene Nachfrage-Null vermittelt ehrlich die (vielleicht irreführende) Information, dass das Produkt im Regal einfach nicht sehr beliebt ist (übrigens: Braucht jemand da draußen einen gebrauchten Kinderwagen?). und die Verfügbarkeits-Null -Wahrscheinlichkeit, die alle möglichen Informationen über die tatsächliche Nachfrage ausblendet – diese Nachfrage hätte null, eins, 14 oder 2.766 betragen können. Es ist klar, dass man die Nachfrage-Nullstellen in das Modelltraining einbeziehen muss, aber man würde enorm darunter leiden, eine Verfügbarkeits-Nullstelle mit einem Mangel an Nachfrage zu verwechseln.
.png%3Fh%3D480%26iar%3D0%26w%3D640&w=1920&q=75)