
















Im ersten Teil dieses Blogbeitrags haben wir zensierte Verkaufswahrscheinlichkeitsverteilungen vorgestellt. Jetzt wollen wir uns die Sache genauer ansehen und herausfinden, was endliche Kapazität in der Praxis bedeutet. Wir beginnen damit, auf subtile Fallstricke hinzuweisen, in die man unabsichtlich tappen könnte, um dann zu erläutern, wie wir die Situation üblicherweise lösen.
Verwechslung von Umsatz und Nachfrage
Ihr Vorgesetzter könnte Sie bitten, diesen Blogbeitrag einfach komplett zu ignorieren, um sowohl ein „erstes einfaches Modell“ als auch eine „grobe Einschätzung der Modellqualität“ zu erhalten. Man könnte tief durchatmen und genau das tun, d. h. die Verkaufszahlen direkt als tatsächliche Nachfrage interpretieren.
Was könnte da schon passieren? Ein naiver Vergleich einer unvoreingenommenen prognostizierten Nachfrage mit den beobachteten Verkäufen führt typischerweise zu dem Urteil „Die Prognose ist verzerrt, sie ist zu hoch angesetzt“: Die begrenzte Kapazität hat den Wert der beobachteten Verkäufe gedrückt. Je häufiger die Kapazitätsgrenze erreicht wird, desto stärker werden die Verkäufe beeinträchtigt. In der Praxis ist besonders schädlich, dass die Auswirkungen begrenzter Kapazitäten je nach Produktgruppe erheblich variieren: Frische Produkte müssen hin und wieder ausverkauft sein, um Verschwendung zu vermeiden, und die Kapazitätsgrenzen werden immer wieder erreicht. Nicht verderbliche Waren werden in der Regel so aufgefüllt, dass sie nie vergriffen sind, und die Lagerkapazität wird fast nie erreicht. Ein Vergleich zwischen Produktgruppen wird immens unter den unterschiedlichen Auswirkungen verschiedener Kapazitäts- bzw. Lagerhaltungsstrategien leiden.
Aber würden wir überhaupt ein unverzerrtes Modell erhalten? Das ist unwahrscheinlich: Beim Training lernt Ihr Modell direkt eine verzerrte Nachfrage. Bei einer vollständigen Nachfrageverteilung mit einem Mittelwert von 9,7 würde das Modell nur die eingeschränkte, zensierte Verteilung lernen, die einen niedrigeren Mittelwert aufweist, wie in der folgenden Abbildung zu sehen ist:

Der Teufelskreis einer zu niedrigen Prognose, die zu einer geringen Bestellung, zu mehr Fehlbeständen und schließlich zu einer noch niedrigeren Prognose führt, beschleunigt sich immer weiter – während die Auswertung bestätigt, dass „alles in Ordnung“ ist und die „Absatzprognose stimmt“. In anderen Situationen können die Kapazitätsengpässe während der Trainings- und Evaluierungsphase aus verschiedenen Gründen variieren, was nachteilige Folgen für die Interpretation der beobachteten Verzerrung (oder deren Fehlen) hat.
Wenn Sie bis hierher gelesen haben, verstehen Sie wahrscheinlich, dass Umsatz und Nachfrage nicht gleichzusetzen sind, und Sie werden in der Lage sein, Ihren Vorgesetzten überzeugend davon zu überzeugen, den längeren, präziseren Weg zu wählen.
Auswahl von Tagen, an denen die Nachfrage nicht erreicht wurde
Die oben genannte Falle ist recht einleuchtend: Nachfrage und Absatz sind unterschiedliche Größen, und sie gleichzusetzen, wenn sie es nicht sind, ist eindeutig problematisch. Die zweite Falle, vor der ich Sie warnen möchte, ist etwas subtiler (vereinbaren Sie ein zweistündiges Gespräch mit Ihrem Vorgesetzten, um sie ihm zu erklären): Eine Idee, die typischerweise in Projekten auftaucht, ist, Modelle nur anhand von Ereignissen ohne Kapazitätsauslastung zu trainieren oder zu evaluieren, d. h. an Tagen, an denen die Verkäufe die Kapazität nicht ausgeschöpft haben. Das heißt, alle Ereignisse, bei denen eine Zensur stattgefunden hat (die Verkäufe entsprechen den Lagerbeständen), werden aus dem Training oder der Evaluierung entfernt, und nur Verkaufswerte, die niedriger als die Kapazität sind, werden beibehalten. Bei den übrigen Ereignissen handelt es sich um unbeschränkte Ereignisse, was, so die Hoffnung, ein unvoreingenommenes Training und eine unvoreingenommene Bewertung ermöglichen soll.
Dies ist jedoch keineswegs der Fall! Durch die Auswahl der Tage, an denen die Kapazität nicht erreicht wurde, wählt man naturgemäß jene negativen Schwankungsereignisse aus, bei denen die Nachfrage zufällig besonders gering war. Das heißt, man führt eine Selektionsverzerrung ein, indem man sich auf diejenigen Ereignisse konzentriert, die negative Ausreißer darstellen. Ein solcher Trainings- oder Evaluierungsdatensatz spiegelt den wahren Bedarf nicht unvoreingenommen wider, sondern erzeugt ein negativ verzerrtes Bild. Bei den Ereignissen, bei denen die Kapazitätsgrenze erreicht wurde, handelt es sich um solche, bei denen die tatsächliche Nachfrage aufgrund von Zufallseffekten etwas höher als der Mittelwert war. Diese Ereignisse wären notwendig, um einen unverzerrten Gesamtwert zu ermitteln. In der folgenden Abbildung sehen wir, warum das Entfernen der Kapazitätsüberschreitungsereignisse sogar noch schlechter sein kann als das Training mit dem gesamten Datensatz der Verkaufswerte (d. h. mit eingeschränkter Nachfrage): Der durchschnittliche Umsatz unter der Bedingung, dass die Kapazität nicht erreicht wird (grüne gestrichelte Linie), ist niedriger als der Gesamtdurchschnittsumsatz (rote Linie), da der durchschnittliche Umsatz bei Kapazitätsüberschreitung (schwarze Linie) zu höheren Werten beiträgt. Zur Erinnerung: Was wir lernen möchten bzw. was wir prognostiziert haben, ist die blau gepunktete Durchschnittsnachfrage.
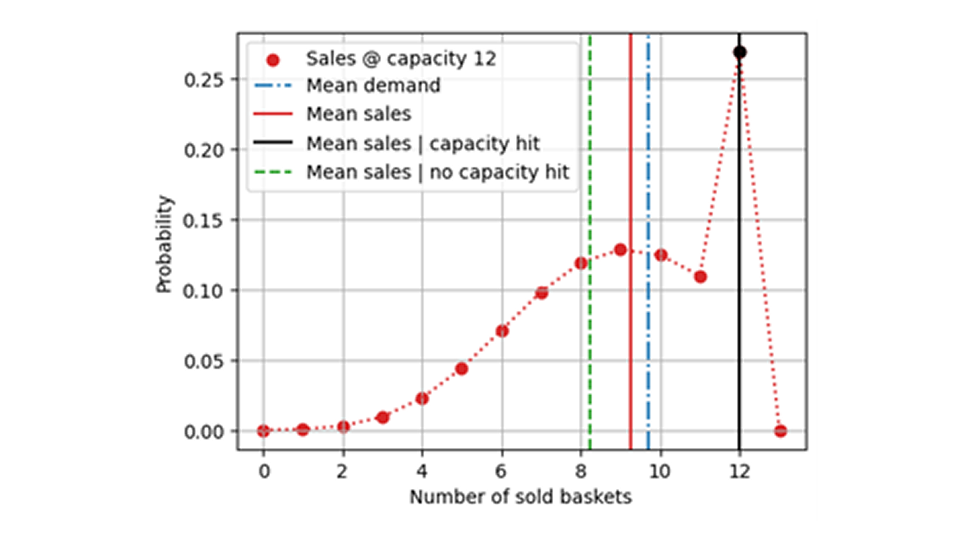
Statistisch gesehen sind die Tage, an denen ein Produkt nicht ausverkauft war, nicht repräsentativ für alle Tage, sondern es handelt sich um Tage, an denen weniger Menschen in den Supermarkt kamen. Vielleicht waren die Erdbeeren nicht frisch, oder eine Werbekampagne für Mangos hat die Leute zum Weggehen veranlasst – in jedem Fall würden wir Ausreißer auswählen und können nicht erwarten, dass diese unvoreingenommen sind!
Falls Sie die umgekehrte Strategie verfolgen und diejenigen Ereignisse auswählen, bei denen die Kapazität erreicht wurde, verzerren Sie Ihren Datensatz noch stärker: Die durchschnittlichen Umsätze haben dann überhaupt nichts mit der Prognose zu tun, da sie genau die Strategie der Kapazitätsfestlegung reproduzieren – die Umsätze entsprechen dann trivialerweise immer der Kapazität.
Die Aufteilung der Auswertungsdaten in „Kapazität erreicht“ versus „Kapazität nicht erreicht“ verstößt auch gegen einen wichtigen Grundsatz der Prognoseauswertung: Daten dürfen niemals nach einem Kriterium aufgeteilt werden, das zum Zeitpunkt der Prognose unbekannt war. Eine solche Aufspaltung führt fast immer zu einer subtilen Selektionsverzerrung in den resultierenden Gruppen. Ein ähnlicher Effekt wird im Blogbeitrag "You should not have always know better" diskutiert.
Wie man die Fallstricke vermeidet
Was das Training betrifft, ist die Schlussfolgerung ernüchternd: Es führt kein Weg an einem „richtigen“ Training mit Methoden wie der Tobit-Regression vorbei, die berücksichtigt, dass die Beobachtung von 12 bei einer Kapazität von 12 nur eine Untergrenze für die tatsächliche Nachfrage an diesem Tag darstellt. Mit anderen Worten, wir benötigen eine Regressionsmethode, die „versteht“, dass 12 verkaufte Artikel bedeuten, dass „12 oder mehr Artikel nachgefragt werden“. Die begrenzte Kapazität führt tatsächlich zu Informationsverlusten – ein Modell, das kapazitätsbeschränkte Umsätze als Eingangsgröße verwendet, wird, selbst wenn es dies korrekt tut, immer weniger präzise sein als ein Modell, das mit unbeschränkter Nachfrage arbeitet.
Bei der Modellevaluierung kann man die endliche Kapazität explizit berücksichtigen: Der erwartete Umsatz bei gegebener endlicher Kapazität kann aus der zensierten Wahrscheinlichkeitsverteilung berechnet werden. Denken Sie daran, dass die erwarteten Umsätze unter Kapazitätsbeschränkungen nicht einfach der kleinere Wert aus „der unbeschränkten Nachfrageprognose“ und „der Kapazität“ sind, sondern dass die gesamte beschränkte Wahrscheinlichkeitsverteilung berücksichtigt werden muss. Man schließt dann mit einem Vergleich wie dem folgenden:
| Mittlere unzensierte Nachfrageprognose | Mittlere zensierte Umsatzprognose | Mean actual sales |
| 17.84 | 14.35 | 14.66 |
In diesem Fall würde man feststellen, dass die tatsächlichen Verkaufszahlen (nach Berücksichtigung der Kapazitätsengpässe) gut mit den Erwartungen übereinstimmen.
Prognostizierte Kapazitätsüberschreitungswahrscheinlichkeit und tatsächliche Kapazitätsüberschreitungshäufigkeit
Obwohl der Vergleich der prognostizierten Umsätze unter Berücksichtigung der Kapazitätsengpässe mit den tatsächlichen Umsätzen dazu beiträgt, die Verzerrung (oder deren Fehlen) der Prognose zu ermitteln und ein guter erster Schritt zur Feststellung ihrer Qualität ist, stößt man häufig auf Skepsis in folgender Form: „Wir erkennen an, dass die Prognose insgesamt unverzerrt ist, befürchten aber, dass sie auf unglückliche Weise sowohl zu Über- als auch zu Unterprognosen führt, was sowohl zu mehr Verschwendung als auch zu mehr Fehlbeständen als nötig führt.“
Mit anderen Worten: Die Akteure im Bereich der Prognosen sind nicht nur an der globalen Unvoreingenommenheit interessiert, sondern an der Unvoreingenommenheit in jeder möglichen Nachfragesituation. Sie wollen die Tage mit besonders hohem Umsatz nicht zu niedrig einschätzen und dies dann durch eine Überschätzung der Tage mit niedrigem Umsatz ausgleichen. Insbesondere wenn die Kapazitätsgrenze erreicht ist, wollen die Beteiligten sicherstellen, dass dies nur geringfügig geschieht (nur wenige Kunden verlassen das Unternehmen, ohne ihre Bedürfnisse befriedigt zu haben); wenn es zu Verschwendung kommt, sollte diese nicht in enormen Mengen auftreten.
Um dieser berechtigten Befürchtung zu begegnen (man kann sich leicht schreckliche Prognosen vorstellen, die global unvoreingenommen sind und zu viel Verschwendung und unzufriedenen Kunden führen), schlage ich vor, die Daten nach der vorhergesagten Wahrscheinlichkeit eines Kapazitätsausfalls zu trennen. Das heißt, ausgehend von einer Prognose und einem bestimmten Lagerbestand, der an diesem Tag installiert wurde, berechnet man die vorhergesagte Wahrscheinlichkeit, dass der Bestand ausverkauft ist – die vorhergesagte Kapazitätsauslastungswahrscheinlichkeit. Die Wahrscheinlichkeit, dass die Kapazitätsgrenze erreicht wird, liegt nahe bei 0, wenn der Lagerbestand im Verhältnis zur Prognose auf einen hohen Wert festgelegt wird (z. B. wenn der Lagerbestand auf das 0,99-Quantil der Nachfrageverteilung festgelegt wird, ist es zu 99 % sicher, dass die Kapazitätsgrenze nicht erreicht wird). Die Wahrscheinlichkeit einer Kapazitätsüberschreitung liegt nahe bei 1, wenn der Lagerbestand gering ist, z. B. wenn er auf das 0,01-Quantil der Nachfrageverteilung eingestellt ist.
Für jede Vorhersage erhalten wir dann eine vorhergesagte Wahrscheinlichkeit, die Kapazität zu erreichen (z. B. 0,42), und eine tatsächliche Kapazitätsüberschreitung (Überschreitung oder Nichtüberschreitung). Ein solches einzelnes Treffer-/Nicht-Treffer-Ereignis ist rein anekdotisch: Die bloße Existenz einiger „unwahrscheinlicher“ Paare „vorhergesagte Kapazitätstrefferwahrscheinlichkeit = 0,05, aber Kapazität wurde tatsächlich getroffen“ bedeutet nicht, dass die vorhergesagte Wahrscheinlichkeit irreführend ist. Nur wenn man über eine Sammlung vieler Wahrscheinlichkeitsvorhersagen und zugehöriger Treffer-/Nicht-Treffer-Ereignisse verfügt, können die vorhergesagten Wahrscheinlichkeiten streng überprüft werden. Dazu sammelt man viele Paare von Kapazitätstreffwahrscheinlichkeiten (Gleitkommazahlen zwischen 0 und 1) und Kapazitätstreffern (diskrete Ergebnisse, 1 für „getroffen“ und 0 für „nicht getroffen“). Diese werden in Gruppen mit vorhergesagter Kapazitätsauslastung von etwa 0, etwa 0,10, etwa 0,20 usw. eingeteilt. Anschließend berechnen Sie für jeden Bucket den Mittelwert der vorhergesagten und der tatsächlichen Kapazitätstrefferrate. Wenn in 0,10 Fällen mit einer Kapazitätsüberschreitung gerechnet wird, gehen wir davon aus, dass in etwa 10 % dieser Fälle die Kapazität tatsächlich erreicht wird.
Wir bezeichnen vorhergesagte Wahrscheinlichkeiten als „kalibriert“, wenn wir ihnen in dem Sinne vertrauen können, dass ein vorhergesagter Kapazitätsverlust von 0,70 in 70 % dieser Fälle eintritt (mehr über Kalibrierung erfahren Sie im Blogbeitrag Kalibrierung und Schärfe: Die zwei unabhängigen Aspekte der Prognosequalität). Eine kalibrierte Prognose ermöglicht strategische Nachschubentscheidungen: Man legt den Lagerbestand so fest, dass man erwartet, dass der Bestand in 0,023 Tagen ausgeht – und tatsächlich geht der Bestand in 2,3 % der Tage aus. Das ist Risikomanagement: Man quantifiziert das Risiko auf eine kalibrierte Weise und geht bewusst jene Risiken ein, die es wert sind, eingegangen zu werden.
In der untenstehenden Abbildung zeigen die schwarzen Kreise einzelne Kapazitätsüberschreitungsereignisse – die Kapazität wurde entweder erreicht (oben in der Abbildung) oder nicht (unten in der Abbildung). Wenn wir alle Vorhersagen zusammenfassen, entspricht die mittlere vorhergesagte Kapazitätstrefferrate von 0,82 der gemessenen Häufigkeit (grüner Kreis). Wenn wir nach der Wahrscheinlichkeit eines Kapazitätsengpasses aufteilen, die nahe bei 0, bei 0,1, bei 0,2 usw. liegt, sehen wir, dass die Prognose des Kapazitätsengpasses kalibriert ist: Die blauen Kreise liegen nahe an der Diagonalen.
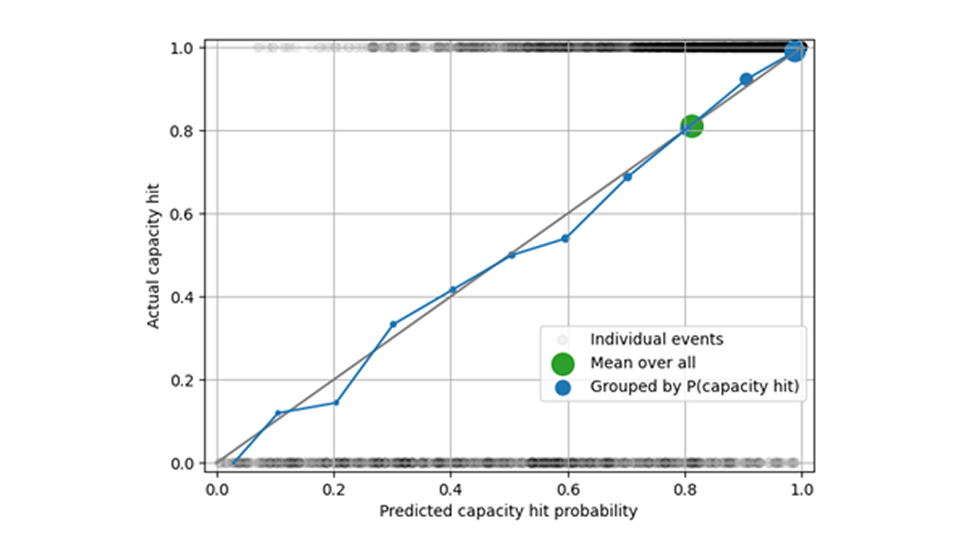
Die Bewertung der vorhergesagten und tatsächlichen Wahrscheinlichkeiten und Häufigkeiten von Kapazitätsengpässen reicht nicht aus, um eine gute Prognose zu gewährleisten: Wenn Sie 1.000 Artikel einlagern, gibt es keinen Unterschied im Verhalten bei Kapazitätsengpässen, egal ob die Prognose 5, 10 oder 100 Artikel vorsieht – in allen Fällen landet das Ereignis in der gleichen Kategorie: „Die Kapazität wird mit Sicherheit nicht erreicht“. Daher sollte eine Analyse der Verzerrung bei den prognostizierten Verkäufen die Analyse der Kapazitätsauslastung ergänzen, um zu überprüfen, ob die Prognose sowohl hinsichtlich der Kapazitätsbeschränkungen als auch der Geschwindigkeiten unverzerrt ist.
Im Allgemeinen folgt die Gruppierung nach der prognostizierten Wahrscheinlichkeit einer Kapazitätsüberschreitung oder nach prognostizierten Umsätzen der Regel „Sei zukunftsorientiert: Bewerte, was du prognostizierst, anstatt rückwärts zu blicken“, um den im Blogbeitrag „You should not have always know better“ beschriebenen Rückschaufehler zu vermeiden.
Fazit: Für ein effektives Risikomanagement sind probabilistische Instrumente erforderlich.
Punktprognosen, die eine einzelne Zahl als Vorhersage liefern, eignen sich nicht zur Beantwortung strategischer Wahrscheinlichkeitsfragen, wie beispielsweise der Frage, welcher Lagerbestand eine Fehlbestandsquote von unter 1 % gewährleisten kann. Wenn man eine Wahrscheinlichkeitsfrage stellt – und alle Fragen zum Thema Risiko sind Wahrscheinlichkeitsfragen –, benötigt man Wahrscheinlichkeitswerkzeuge, um sie zu beantworten. Sie müssen Ihrem Vorgesetzten zumindest ein grundlegendes Verständnis von „Erwartungswert“, „Zensierung“ und „Verteilung“ vermitteln.
Immer wenn die Kapazität Auswirkungen auf die reale Welt hat (und das hat sie fast immer), müssen wir die Kapazitätsbeschränkungen ernst nehmen. Wir sollten nicht versuchen, Ereignisse im Nachhinein zu verstehen („Die Kapazität wurde an diesem Tag erreicht, was war die genaue Ursache?“), sondern wir sollten nach vorne blicken und die Kalibrierung der Prognosen bewerten, indem wir sie nach prognostizierten Umsätzen und prognostizierter Wahrscheinlichkeit eines Kapazitätsengpasses aufschlüsseln.
Alle Beispiele in diesem Blogbeitrag wurden in einer Sandbox-ähnlichen Umgebung erstellt, wobei von einer perfekten Nachfrageprognose ausgegangen wurde, die zu einer gutartigen Verteilung führt. Ich habe dich vor allen komplexeren Problemen abgeschirmt, denen du typischerweise in realen Situationen begegnen würdest. Doch selbst in diesem einfachen Szenario sehen wir, wie leicht sich unsere Intuition täuschen lässt. Daher ist es wichtig, nicht einfach der allerersten Idee zu folgen, die einem bei der Lösung eines Bewertungsproblems in den Sinn kommt („Lasst uns einfach nach Kapazität erreicht versus Kapazität nicht erreicht gruppieren“), sondern eine skeptische Perspektive einzunehmen und zunächst zu simulieren , was die Methode in einem idealen Umfeld bewirken würde.
