
















Es wurde viel darüber gesprochen, wie generative KI die Arbeit in der Lieferkette verändern wird. Bei Blue Yonder wollten wir diese Auswirkungen im Rahmen einer Benchmarking-Studie untersuchen. In unserem Forschungsexperiment haben wir untersucht, wie leistungsfähige Large Language Models (LLMs) out-of-the-box sind – und ob sie effektiv auf die Supply-Chain-Analyse angewendet werden können, um die wirklichen Probleme im Supply-Chain-Management anzugehen.
LLMs, einschließlich ChatGPT, sind eine Art künstlicher Intelligenz, die mit riesigen Datenmengen trainiert wird und es ihnen ermöglicht, die Muster, Grammatik und Semantik der Sprache zu lernen. In den letzten Jahren sind LLMs stark gewachsen und werden weltweit in einer Reihe von Anwendungen eingesetzt, darunter die Erstellung von Inhalten, der Kundenservice und der Marktforschung.
IDC-Daten zeigen, dass die Software- und Informationsdienstleistungs-, Banken- und Einzelhandelsbranche im Jahr 2024 voraussichtlich rund 89,6 Milliarden US-Dollar für KI bereitstellen wird, wobei generative KI mehr als 19 % der Gesamtinvestitionen ausmacht.
Diese sich schnell entwickelnde Technologie bietet Unternehmen mehr Kreativität, Effizienz und Entscheidungsfähigkeit – die das Potenzial haben, Branchen und Prozesse zu revolutionieren. Wie gehen LLMs derzeit mit Supply-Chain-Situationen um?
Über die generative KI-Benchmark-Studie von Blue Yonder
Unser generativer KI-Supply-Chain-Test basiert lose auf dem viralen ChatGPT-Experiment namens Uniform Bar Examination. In dieser Studie bestand die neueste Version von ChatGBT die Anwaltsprüfung mit einer hohen Gesamtpunktzahl von 297 und näherte sich damit dem 90. Perzentil aller Testteilnehmer. Indem LLMs die Messlatte mit einer Punktzahl von fast 10 % bestehen, demonstrieren sie die Fähigkeit generativer KI, rechtliche Prinzipien und Vorschriften zu verstehen und anzuwenden. Diese bahnbrechende Studie löste weltweit Diskussionen aus und unterstrich das transformative Potenzial von KI.
Blue Yonder beschloss, dieses Gespräch noch einen Schritt weiter zu führen, indem es untersuchte, wie führende LLM-Systeme bei Prüfungen in der Supply-Chain-Branche abschneiden können. Wir ließen LLMs gegen zwei Standardzertifizierungstests antreten, den CPSM und den CSCP. Unser Ziel? Um zu sehen, ob LLMs als Supply-Chain-Profis fungieren können, indem sie die Nischenregeln und den Kontext der Supply-Chain-Branche ohne Schulung verstehen.
Wir haben das Experiment so konzipiert, dass jedes LLM programmgesteuert die Übungstests durchlaufen wird, ohne Kontext um den Test herum, ohne Zugang zum Internet und ohne Programmierkenntnisse. Wir wollten bewerten, wie die LLMs direkt nach dem Auspacken abschneiden würden, um eine konsistente und unvoreingenommene Bewertung zu ermöglichen.
Sowohl die CPSM- als auch die CSCP-Zertifizierungstests sind Multiple-Choice-Prüfungen. Anstatt dass die LLMs einfach eine Antwort auswählen, haben wir eine Ausgabe für die Modelle eingerichtet, um jede von ihnen ausgewählte Auswahl zu erklären. Dieser Ansatz ermöglichte es uns, wertvolle Einblicke in den Denkprozess jedes Modells zu gewinnen und zu verstehen, warum es falsche oder richtige Antworten gab, was uns half, die Fähigkeiten jedes Modells zu bewerten.
Nachdem aktualisierte Versionen der LLMs veröffentlicht wurden, haben wir den Test diesen Sommer erneut durchgeführt, um neue Benchmark-Ergebnisse zu sammeln.
Können LLMs also Supply-Chain-Prüfungen bestehen?
Beeindruckend ist, dass die LLMs bei den Supply-Chain-Prüfungen ohne Schulung überraschend gut abgeschnitten haben. Wir haben uns zunächst die Out-of-the-Box-Leistung von LLMs ohne Kontext angesehen und dann einige Vorteile hinzugefügt.
Stufe 1: Kein Kontext, kein Internetzugang, keine Programmierkenntnisse
Während die meisten Modelle ohne Kontext eine solide Bestehensnote erreichten, stach Claude 3,5 Sonnet hervor und sicherte sich beim CPSM-Zertifizierungstest eine beeindruckende Genauigkeit von 79,71 %. Bei der CSCP-Prüfung setzten sich die Modelle o1-Preview und GPT 4o von OpenAI mit einer Genauigkeit von 48,30 % gegen Claude Opus durch, verglichen mit 45,7 % bei letzterem.
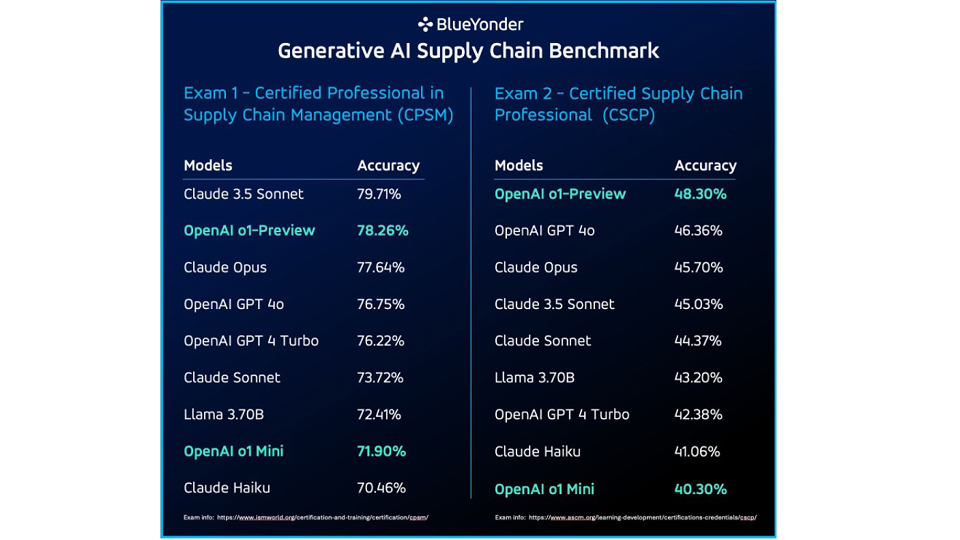
LLMs schnitten zwar in bestimmten Bereichen gut ab, wiesen aber auch Einschränkungen auf, insbesondere wenn es sich um mathematikbezogene Fragen oder stark domänenspezifische Fragen handelte.
Bei der Untersuchung nur der mathematischen Probleme in jeder Zertifizierungsprüfung zeigte OpenAI o1 Mini eine signifikante Verbesserung der Genauigkeit für OpenAI-Modelle und übertraf die getesteten Claude-Modelle.

Diese Ergebnisse wurden ohne Kontext, ohne Internetzugang und ohne Programmierkenntnisse generiert. Als Nächstes untersuchten wir, was passieren würde, wenn wir anfangen würden, den LLMs mehr Unterstützung zu geben.
Schritt 2: Hinzufügen eines Internetzugangs
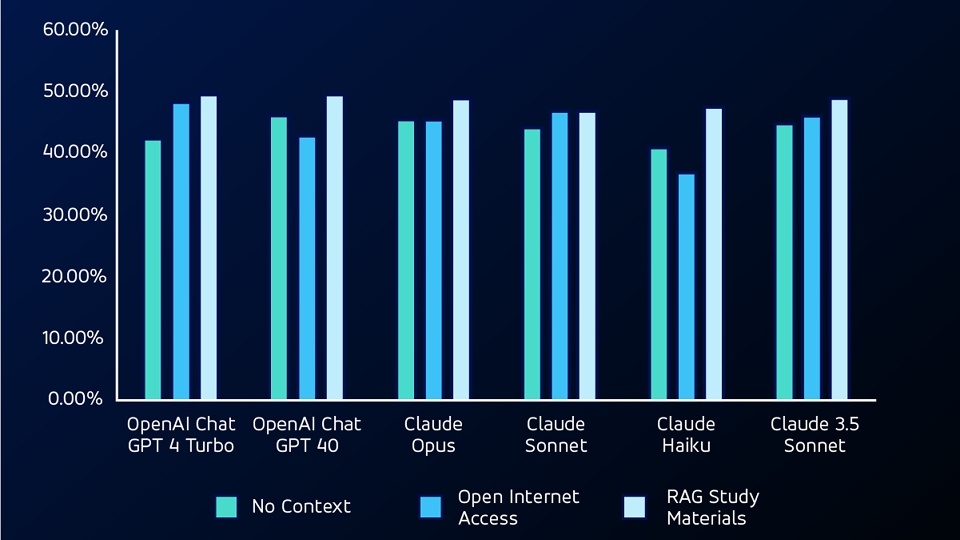
In der nächsten Testphase haben wir den LLM-Programmen Zugang zum Internet gegeben, sodass sie mit you.com suchen können. Mit dieser zusätzlichen Funktion erzielte OpenAI GPT 4 Turbo den deutlichsten Fortschritt – von 42,38 % auf 48,34 % – beim CSCP-Test.
Bei der Betrachtung von Fragen, die beim ersten No-Context-Test zunächst übersehen wurden, erreichte das Claude-Sonnet-Modell eine Genauigkeitsbewertung von etwa 53,84 % für die CPSM-Fragen und 20 % für die CSCP-Fragen.
Der Internetzugang ermöglichte es den Modellen zwar, unabhängig voneinander nach Informationen zu suchen, führte aber auch zu Ungenauigkeiten aufgrund unzuverlässiger Online-Informationsquellen.
Phase 3: Bereitstellen des Kontexts mit den Regionalbeihilfen
Für den nächsten Test verwendeten wir ein RAG-Modell (Retrieval Augmented Generation), das den LLMs Studienmaterialien aus den Tests zur Verfügung stellte. Unter Verwendung von RAG übertraf das LLMS sowohl den No-Context- als auch den Open-Internet-Access-Test bei nicht-mathematischen Fragen und erzielte bei beiden Tests die höchsten Genauigkeitswerte.
Stufe 4: Hinzufügen von Programmierfähigkeiten
Für den nächsten Test gaben wir den Modellen schließlich die Möglichkeit, ihren eigenen Code mit den Frameworks Code Interpreter und Open Interpreter zu schreiben und auszuführen.
Mit diesen Frameworks konnten die LLMs Code schreiben, um die mathematischen Fragen in den Prüfungen zu lösen, mit denen sie in der ersten Iteration des Tests zu kämpfen hatten. Mit ihren Codierungsfähigkeiten übertrafen die LLMs den No-Context-Test um durchschnittlich etwa 28 % in der Genauigkeit aller Modelle für mathematische Fragen.
Sind LLMs nützlich, um Probleme in der Lieferkette zu lösen?
Im Großen und Ganzen haben die LLM-Systeme die branchenüblichen Supply-Chain-Prüfungen bestanden. Diese Leistung stellt eine sehr spannende Möglichkeit dar, LLMs in das Supply Chain Management zu integrieren. Perfekt sind die Modelle allerdings noch nicht. Sie hatten sowohl mit mathematischen Problemen als auch mit einer spezifischen Logik der Lieferkette zu kämpfen.
Mit der zusätzlichen Fähigkeit, Code zu schreiben, waren die LLMs in der Lage, viele der mathematischen Probleme zu überwinden – benötigten aber immer noch einen sehr spezifischen Kontext in der Lieferkette, um einige der komplexeren Fragen innerhalb der Prüfungen zu lösen.
Unsere Studie hat gezeigt, dass generative KI mit den richtigen Tools und Schulungen äußerst nützlich sein kann, um Probleme in der Lieferkette zu lösen.
Glücklicherweise ist es das, was Blue Yonder auszeichnet. Wir haben es uns zur Aufgabe gemacht, die Leistungsfähigkeit der generativen KI zu nutzen, um praktische, innovative Lösungen für Herausforderungen in der Lieferkette zu entwickeln. Unser neu gegründetes AI Innovation Studio ist eine Drehscheibe für die Entwicklung dieser Lösungen und schließt die Lücke zwischen komplexen KI-Technologien und realen Anwendungen.
Unser Fokus liegt auf der Entwicklung intelligenter Agenten, die auf bestimmte Rollen innerhalb der Lieferkette zugeschnitten sind, um sicherzustellen, dass diese Agenten in der Lage sind, die echten, authentischen Probleme und Herausforderungen zu lösen, mit denen wir gerade konfrontiert sind. Erfahren Sie mehr über KI und maschinelles Lernen bei Blue Yonder oder kontaktieren Sie uns , um ein persönliches Gespräch zu beginnen.
